
なぜ機械学習を利用したカスタムOCRソリューションを開発するのですか?
OCRは今日のERPシステムでの「テクノロジーの話題」となっています。OCRとは、Optical Character Recognitionの略です。その役割は、顧客の注文書、レシート、請求書、スキャンされたレポートなどの入力文書をデジタルデータに変換することです。このデータはERPシステムで自動的にアクセスおよび編集することができます。OCRはデジタルスキャニングの方法を驚くほど向上させました!
進化
これは「情報時代」です。今日私たちが知っているすべてが知能に基づいています。だから、なぜOCRにもそうでないのでしょうか?
通常のOCRはある程度まで価値があります。しかし、ある程度の段階で、その限界に達します。通常のOCRは、複雑で構造化されていない文書を処理することができません。もし、どのように文書から何を把握し、何を自動処理するかをOCRが知っていたらどうでしょうか?それは画期的ではないでしょうか? OCRに「自らの脳」を与えることで、非構造化の複雑でノイズの多いデータも容易に読み取ることができます。
ML駆動のOCRが提供するもの:
- 高精度な抽出
- 任意のレベルへの文書分類
- データのクリーニング
- データの検証
- 文脈の保存
- 予測的な洞察
- 異常検知
- 洞察の生成
未来の市場
Transparency Market Researchによると、2025年末までにOCR産業の価値は251.8億ドルに達し、2017年から2025年まで年平均14.8%の成長が見込まれています。
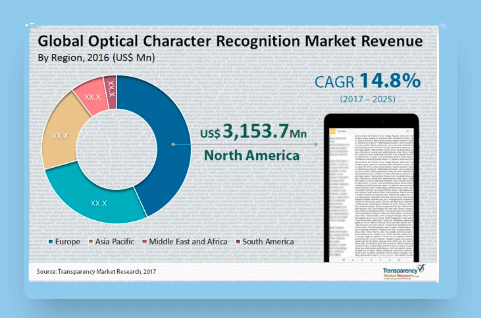
また、2017年から2025年までの期間に、アジア太平洋地域のOCR市場は市場を15.6%上回ると予想されています。デジタル化の普及と光学文字認識ソフトウェアの利用可能性の増加が、アジア太平洋市場の促進要因となっています。中国とインドの急成長市場は、言語の多様性と技術への投資を考慮すると、その先頭に立っています。
nCircleのML駆動OCR
nCircleは世界クラスの3Dエンジニアリングソフトウェア企業で、人工知能の支援を受けてOCRを開発しました。当社のML駆動OCRソリューションは、オブジェクトを「全体」として見て、文書上のすべての利用可能なデータをスキャンし、各単語を相互に関連付けて考慮します。当社のソフトウェアは理解と簡素化の空白を埋めるように設計されています。利用可能なデータを使用して学習する当社のMLベースのOCRは、「人間のような」レベルにあります。
当社の先進的なMLベースのOCRには、以下の利点があります:
- 高速検索 - 情報が一度保存されると、従業員は同じ情報を検索することでいつでもアクセスできます。
- エラーの削減 - すべてのデータがスキャンおよび検証されるため、従業員によって修正中に発生する可能性のあるエラーが削減されます。
- 手動入力の排除 - スキャンによってデータを自動的にキャプチャすることで、手動入力を排除します。そのため、従業員の労力と時間をコアコンピテンシーに集中させることができます。
- 効率性と経済性 - OCRは、印刷、コピー、ファイルキャビネットに関連するさまざまな費用を削減します。そのため、必要なアクセサリーに費用を充てることができます。
- 即時利用可能性 - すべての予定されたタスクは時間通りに実行されるため、ビジネスが計画や戦略に従い、指定された期間内に望ましい目標を達成できます。
当社のML駆動OCRに関する詳細な洞察を得るには、最近の「ブログ投稿」をご覧ください。
ユーザーケースのシナリオ
大規模な建設プロジェクトでは、数千の文書が生成され、注意深い管理が必要です。文書の分類は文書管理および制御における重要なステップです。建設文書はさまざまな形式で生成され、その多くは構造化されておらず、図面や画像が含まれているため、文書の分類と制御のタスクはさらに困難になります。
このシナリオでの当社のMLベースのOCRの実績を見てみましょう。
概要:
現場エンジニアや請負業者は、資産のプレートやラベルから利用可能なテキストデータを手動で検証し、コピーする必要があります。この作業を手動で行うと、人為的なエラーや時間の浪費が生じ、効率が低下します。
したがって、この特定の組織の主要なワークフローには、承認された提出物から取得した情報を使用して資産データを入力することが含まれます。次に、モバイルアプリを使用して、データを資産の銘板と照合し、正しい資産が取り付けられていることを確認します。さらに、銘板からのシリアル番号や製造業者のデータなどの追加データもキャプチャして記録します。
では、技術が組織のスムーズなワークフローを達成するためにどこで失敗したのでしょうか? 従業員がデータキャプチャを手動で処理していたため、多くのエラーが発生し、生産性が低下し、リソースや労働力が浪費されました。
要件:
彼らは、次のようなソリューションが必要でした:
- ワークフローを補完し、データの検証および収集プロセスをより迅速で容易に、かつかなり正確に行うことができるもの。
- 名板のスタイルやレイアウトの無限の変化を横断してデータを識別および抽出する能力。
- 明確なラベルの付いた標準の白黒画像だけでなく、明確な識別子のないエンボス加工された紙や金属プレートなどの画像も処理する能力。
- 明確なラベルのない画像や、照明不足、焦点のずれ、画質の低さ、カメラの角度の観点からの画像も処理する能力。
解決策:
当社のOCRソリューションの支援を受けて、組織は要件を達成することができました。当社のソリューションは、大量の建設画像を適切に分類されたテキスト形式にキャプチャおよび変換しました。これにより、提出物からキャプチャされた情報を検証し、シリアル番号や製造日などの追加フィールドを入力するのに役立ちました。この形式は編集、拡張、共有が容易になりました。これにより生産性が向上し、文書化が改善され、効率性が向上しました:
- データの解釈における精度
- 1つの文書内での複数の配置や方向にもかかわらずテキストを読み取る能力
結果:
2020年までに、組織は総額50億ドル以上の建設プロジェクトに参加すると推測されます。これらのプロジェクトから、およそ5万件の名板処理が必要な資産の配送が行われる見込みです。
時間の節約と精度:
従来の手動の検証とデータキャプチャでは、資産の名板データの処理には平均で2分かかりました。これには既存の情報の検証、新しい情報の入力、およびオフィスでの後処理の検証が含まれています。しかし、新しいMLソリューションを使用すると、平均して4秒で処理が完了します。そのため、約1600人時間が節約されました。MLベースのOCRを使用することで、組織はデータエラーが70%以上減少したことを確認しました。
nCircleのOCRがGoogleやAzureのOCRに選ばれた理由は、次のとおりです。?
GoogleやAzureのOCRは、彼らが解釈したテキストを提供します。従来のOCRソリューションが一連の文字を提供するのに対して、nCircleのOCRはこれらを相関させ、モデル番号に対応するはずの文字をマッピングしようとします。これはまた、このプロセスの間に人間の介入がないことを意味し、したがってプロセスをはるかに簡単にします。
また、nCircleのOCRエンジンは建設データに特化しています。一般的なOCRエンジンと比較して、より高い精度を持っています。何千もの銘板がOCRエンジンのトレーニングに使用され、必要なデータを論理的に特定することができるようになっています。
締めくくりの言葉
当社のML駆動のOCRが限界を超え、文書のスキャンに正確で迅速な応答を提供する方法について読んでいただいたと思います。なぜAutodesk University 2020に参加して、さらに詳しく知らないでしょうか。また、当社のウェブサイトにアクセスして、ビジネスにとってのさらなる利点や範囲を見てみましょう。利点や範囲をチェックし、私たちとつながりを持って、影響力のある3Dエンジニアリングおよび建設ソリューションを作り出すことでリードし続けることができるようにしましょう。